All-In-One
AI Compute Platform Fusing CPU + GPU + NPU
AI-Optimized
RISC-V Computing
RISC-V Computing
The All-In-One chip architecture integrates Atrevido CPU, Vector Unit, Tensor Unit, and Gazzillion Misses™ for scalable, programmable AI processing
AI-Optimized
RISC-V Computing
RISC-V Computing
Offered with:
Atrevido
Tensor Unit
Vector Unit
Avispado
All-In-One chip architecture for the future of AI
The AIO AI Compute Platform is the next evolution in AI acceleration, integrating multiple functions into a unified, zero-latency processing system. Built on RISC-V, this All-In-One solution eliminates the inefficiencies of traditional AI architectures, providing seamless scalability from edge AI devices to massive datacenter AI processors.
Tensor Unit
Ultra-Fast AI
Power efficiency
Supports transformers
More on Tensor Unit
Vector Unit
Up to 2048-bits
RISC-V OOO
Customizable
More on Vector Unit
Gazzillion Misses™
Maximizes bandwidth
For Big Data, AI, HPC
More on Gazzillion™
CPU Cores
64-bit Cores
RISC-V OOO
AXI / CHI
Fast unaligned
More on Atrevido
Fusing
CPU + GPU + NPU
Tensor Unit
Ultra-Fast AI
Power efficiency
Supports transformers
More on Tensor Unit
Vector Unit
64-bit
RISC-V OOO
100% Customisable
More on Vector Unit
Gazzillion™
Maximises bandwidth
For Big Data, AI, HPC
More on Gazzillion™
Atrevido
64-bit Core
RISC-V OOO
AXI / CHI
Fast unaligned
More on Atrevido
-
Customisable Core: Tailored Precision
Our Atrevido Core technology allows for precise adaptation to specific AI workloads. This flexibility ensures that each AI chip can be fine-tuned to meet the unique demands of various applications, enhancing performance and efficiency.
-
Vector Unit: Accelerated Data Processing
The Vector Unit integrates advanced data processing capabilities, enabling rapid and efficient handling of complex computations. This component is essential for tasks requiring high-speed data manipulation, ensuring smooth and responsive AI operations.
-
Tensor Unit: Optimised AI Performance
Our Tensor Unit is designed to maximise the performance of AI algorithms, particularly in deep learning applications. By optimising the handling of matrix operations, this unit significantly boosts the efficiency and speed of AI computations.
-
Gazzillion Misses™: Unmatched Scalability
The Gazzillion technology ensures that our AI IP can scale seamlessly to meet the demands of next-generation applications. With its robust architecture, Gazzillion supports the integration of vast numbers of processing units, delivering zero latency.
Ultra-Fast AI
Delivers Ultra-Fast AI solutions
64-bit Core
Integration
Optimised to integrate with our 64-bit cores
Vector Unit and
Gazzillion Misses™ Integration
Seamless integration with our Vector Unit and Gazzillion Misses™
Universal RISC-V Compatibility
Works under any RISC-V vector-enabled Linux without any changes
DMA-Free
Programming
Easy to program as no DMAs needed
Power
Efficiency
Low power consumption
Key Features
Scalable, Limitless AI Processing
Fully Integrated AI Compute
Unifies CPU, Vector, Tensor, and Memory Acceleration for optimal performance.
Scales from 1 to 100s of TOPS
Configure the ideal mix of cores for your workload.
Single, Unified
RISC-V Software Stack
Avoid vendor lock-in with fully programmable AI acceleration.
Zero-Latency Data Flow
No bus congestion, no bottlenecks—just direct communication between all processing units.
Redefining AI Hardware for Unlimited Innovation
Flexibility and power without limits
Unlike conventional AI chips that rely on fixed-function accelerators, AIO is built for full programmability, ensuring it adapts to evolving AI models through software updates.

More Efficient
Eliminates wasted compute cycles with zero-latency interconnects.

More Scalable
Customizable configurations allow AI processing from small edge devices to high-performance AI clusters.

More Flexible
Tailor the CPU-to-Vector-to-Tensor ratio to balance performance and power efficiency.
Instead of using rigid fixed-function accelerators, AIO enables fully flexible AI compute that adapts to future AI breakthroughs. By leveraging our Configurator tool, you can fine-tune the right balance of CPUs, Vector Units, and Tensor Units to achieve optimal PPA (Performance, Power, and Area).
Zero latency and Gazzillion for
ultra-fast performance
Our revolutionary new AI architecture directly interconnects our blocks so zero latency. The data is in the vector registers and can be used by the vector unit or the tensor unit with each part simply waiting in turn to access the same location as needed.
Everyone else requires considerable data movement between different functional blocks via a bus which creates significant performance bottlenecks and latency. Plus, Gazzillion ensures huge amounts of data can be handled from anywhere in the memory without suffering from cache misses.
Easy-to-use, single, simple, unified RISC-V software stack
Instead of IP blocks and tool chains from different vendors to make a current AI solution that makes programming the three totally different software stacks very complicated, our innovative All-In-One AI processor element uses the RISC-V instruction set and a single development environment giving a single software stack to reduce development costs and time. The All-In-One AI IP is thus a big step forward in programmer friendliness as it is designed to simplify programmability so any developer can leverage its full potential.
Scalable, versatile, customisable and future proof
The RISC-V core inside our All-In-One AI IP provides the ‘intelligence’ to adapt to today’s most complex AI algorithms and even to algorithms that have not been invented yet! Instead of using fixed-function accelerators, it is built out of many fully programmable IP elements. Therefore, it is much more resilient and adaptable to future improvements in AI/ML algorithms. This guarantees it will stay relevant over time, being able to adapt to new models and deep learning architectures via software updates.
The Tensor Unit provides the sheer matrix multiply capability for convolutions, while the Vector unit, with its fully general programmability, can tackle any of today’s activation layers as well as anything the AI software community can dream of in the future.
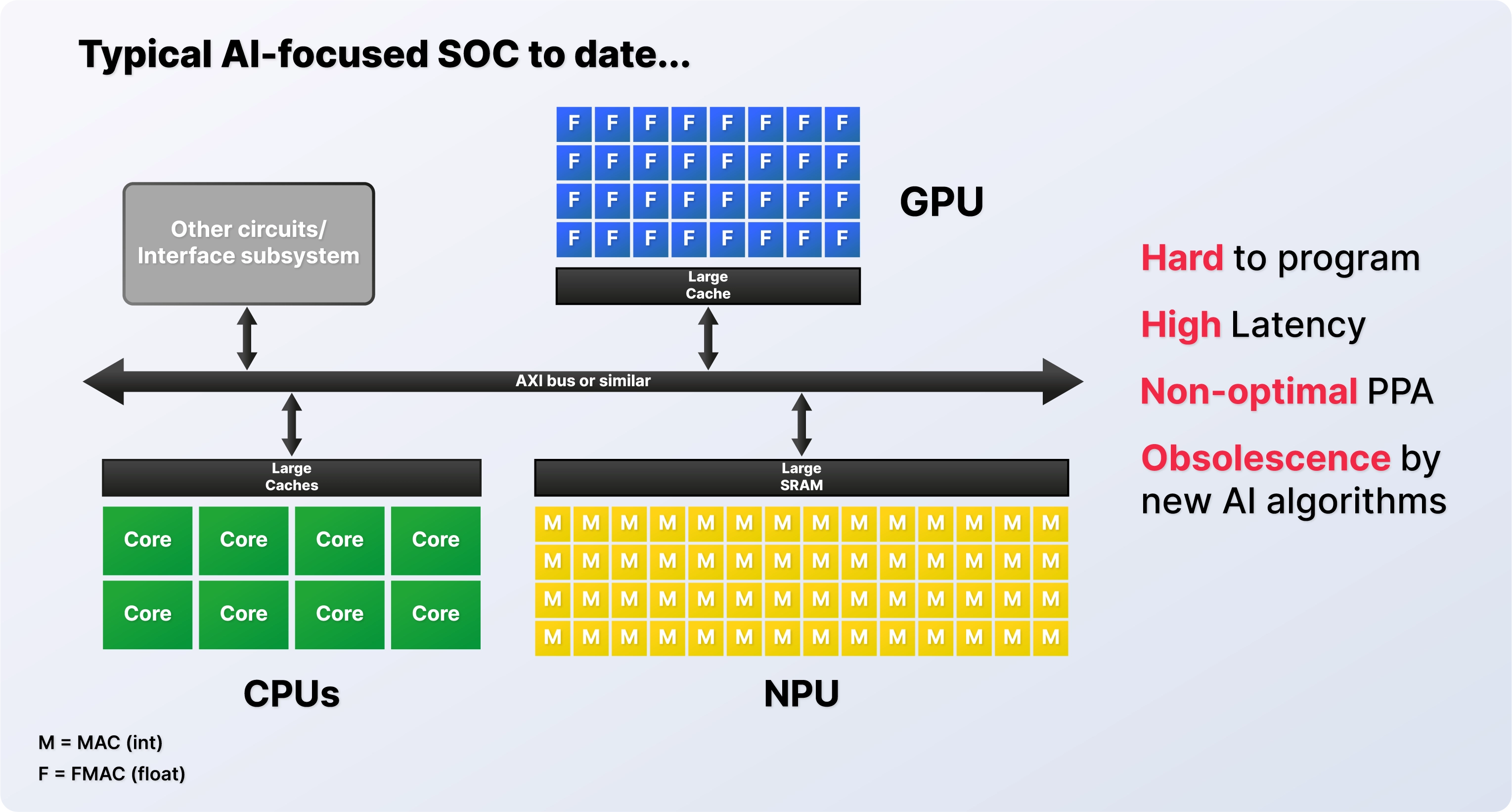
By using our new Configurator tool, you can create the appropriate balance of Tensor and Vector units with RISC-V control capabilities in the processing element to optimise performance and PPA. Having an All-In-One processing element that is simple and yet repeatable solves the scalability problem so you can scale from a 1/4 TOPS to hundreds of TOPS by using as many processing elements as needed on the chip.
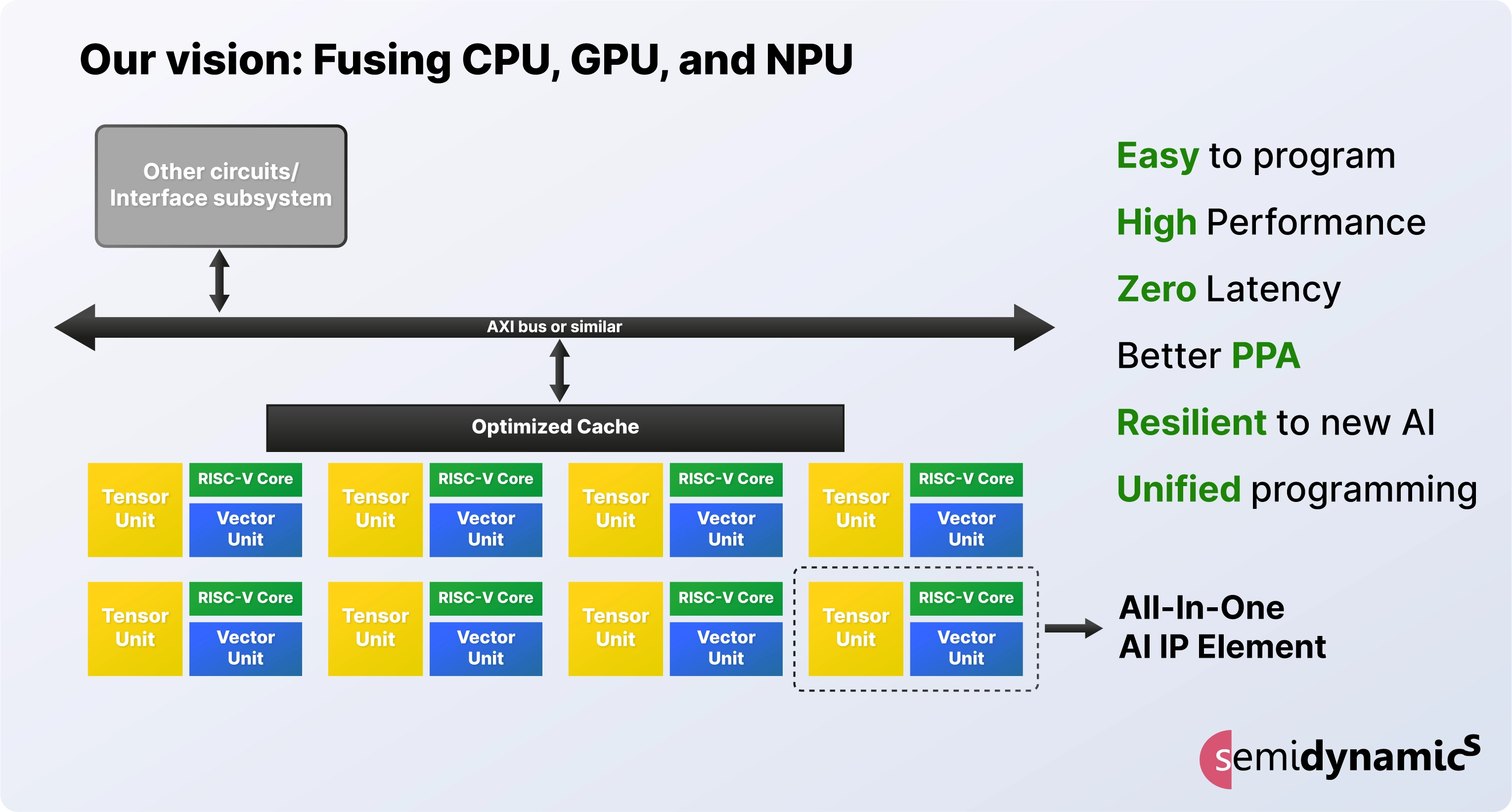
This fully customisable solution sets a new standard for next generation, ultra-powerful AI chips giving you the versatility to create unique solutions to precisely meet your application needs rather than using standard off-the-shelf chips.
And, of course, our Open Core Surgery means that you can have special instructions inserted into the core for even more differentiation!