Avispado
In-Order
Efficient RISC-V Core
Efficient RISC-V Core
A highly efficient and power-conscious core, ideal for AI edge and embedded applications.
In-Order,
Efficient RISC-V Core
Efficient RISC-V Core
A highly efficient and power-conscious core, ideal for AI edge and
embedded applications.
A highly efficient and power-conscious core,
ideal for AI edge and embedded applications
64-bit In-Order Execution
Optimized for energy efficiency.
Vector-Ready
Supports RISC-V Vector Specification 1.0 for AI acceleration.
Ideal for
Machine Learning, Edge AI, IoT, and embedded computing.
Multiprocessing Support
Scalable to multi-core implementations, Linux Ready.
High Bandwidth Access
Gazzillion Technology™ ensures efficient data movement with up to 64 simultaneous memory requests.
Characteristics
64-bit Core
(RISCV64GCV)
(RISCV64GCV)
2-wide In-Order
Multiprocessor Ready
(AXI/CHI)
(AXI/CHI)
Direct hardware support for unaligned accesses
MMU Linux Ready
Available extensions
Customisable options
Branch Predictor
Vector spec 1.0 (vector ready)
I$ from 8KB to 32KB
D$ from 8KB to 32KB
Gazzillion Misses™
more info
more info
Multiprocessor Ready
Avispado supports cache-coherent Multiprocessing environments. Its native CHI interface can be tailored down to AXI, depending on your needs.
Be it 2, 4, or hundreds of cores, Avispado is ready for your next SOC.
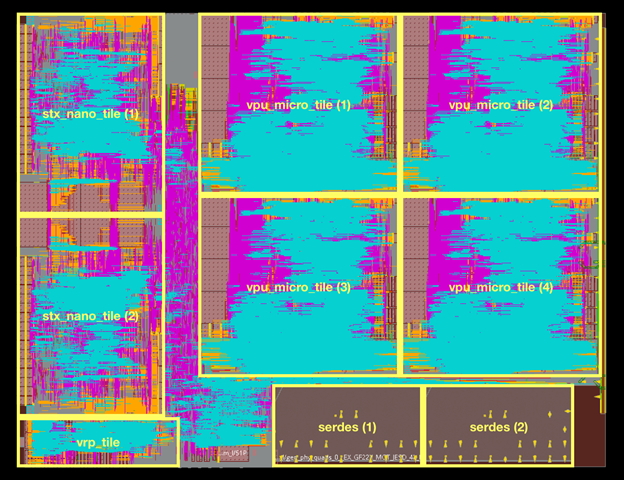
Avispado Test Chip